








製品概要
WordMiner™とは
 WordMiner™(ワードマイナー)は、主に、社会調査や市場調査などの分野で扱う自由回答・自由記述型データ、あるいは、コール・センターやコンタクト・センター、カスタマー・センターなどに収集・蓄積されたテキスト型データなど、テキスト型データが現れる様々な場面において、「現場のデータ解析」を支援するための探索型のマイニング・ツールです。
また、産学協同研究グループの永年の現場体験から得たノウハウを設計思想に反映させ、定性情報に潜在する構造や関係を効果的に探査し、その解釈を容易にするための豊富な機能を備えたツールです。
WordMiner™(ワードマイナー)は、主に、社会調査や市場調査などの分野で扱う自由回答・自由記述型データ、あるいは、コール・センターやコンタクト・センター、カスタマー・センターなどに収集・蓄積されたテキスト型データなど、テキスト型データが現れる様々な場面において、「現場のデータ解析」を支援するための探索型のマイニング・ツールです。
また、産学協同研究グループの永年の現場体験から得たノウハウを設計思想に反映させ、定性情報に潜在する構造や関係を効果的に探査し、その解釈を容易にするための豊富な機能を備えたツールです。
WordMinerの設計指針と特徴
テキスト型データの解析時に発生する様々な事象を想定した記述的多次元データ解析を設計指針の基盤としています。形態素解析(とくに日本語文章の分かち書き処理)と多次元データ解析の要素技術を有機的に組み合わせた新たなデータ解析手法を採用し、とくに、属性項目・選択肢型設問などを自由回答と併せて分析するための多彩な機能を搭載した、実用データ解析に適した探索的マイニング・ツールを目指しております。
(1) 独自の分かち書き処理による「構成要素」の抽出
分かち書き処理・キーワード抽出処理により、テキスト型データを分析が可能な「構成要素」に分解します。「構成要素」とは、厳密な意味での単語・語句を構成する単位ではなく、データ解析上の処理を簡便化するためのある単位を表し、一般に言う単語や語、文節などより緩やかな意味として位置づけております。分かち書き処理・キーワード抽出処理は、Happiness/AiBASE(富士通Japanソリューションズ東京株式会社開発)を採用しています。
(2) 類型化による規則性の探査と個別意見や回答別意味の把握
テキスト型データを解析する目的の一つは、集積した自由回答や自由記述データに潜在する構造(類似性や差異性など)を探査しその規則性を知ることにあります。ここでは、個々の回答や記述の意味内容と特徴、意見の規則性や典型を知ると同時に、類型・典型に含まれる個々の回答データの特徴を読み取ることや、少数例・特異例の特徴も知ることを支援します。WordMinerを利用することにより、テキスト型データ内の意見の客観的な類型化とその内容の解釈が容易になります。
(3) 多次元データ解析手法の採用
統計的方法論として実績のある対応分析法、クラスター化法、及びそれに関連した統計処理を採用しています。多変量解析手法などの数理的な意味と制約を理解して利用することで、解析内容の透明化が図れます。
(4) 定性的調査と定量的調査の併用
従来型の選択肢型設問項目や属性項目などと自由回答設問とを併用し、自由回答の分析結果に加えて、これらの定量型設問項目との相互関連性の検証を行うことができます。自由回答の解析結果に客観的な保証を与えるため、また従来の標本調査の理論や知識を適用できることと併せて、既得の知識情報が反映できる仕組みが必須です。
(5) 数値計算処理上の工夫
扱うデータ行列がきわめて「疎」となること、「はずれ値」への手当が必要なこと、データ表の大きさが不定であること(構成要素が確定しないと解析対象となる行列の大きさが確定しないこと)、大量データの分類を扱うことなど、テキスト型データ解析における数値計算上の工夫が施されています。また、不要語句や単語の削除、類似単語・類語の置換など、出現頻度による閾値指定など、解析目的に応じて、構成要素をきめ細かく反復編集できる辞書編集の仕組みを提供しております。
WordMinerの主な機能
(1) データ・インポート
CSV形式やタブ区切り形式、さらに任意の区切り文字(記号)により区切られた多変量型データ構造一般のファイルをウィザード形式により読み込ます。また、1行目(先頭のレコード)を変数名として読み込むことができます。
(2) 変数の生成
自由回答・自由記述文を分かち書きして構成要素(単語や語句など)変数を生成するとともに、選択肢型設問や属性データから質的変数を生成します。また、ここで生成した構成要素変数同士の併合、質的変数同士の合成などにより新たな変数を生成することもできます。また、クラスター化により、クラスター変数を生成することもできます。
(3) 構成要素の編集・抽出、辞書機能
分かち書き基準やキーワード抽出基準の設定、あるいは、編集辞書機能による分かち書き結果の訂正、不要語句や単語の削除、類似単語・類語の置換など、構成要素をきめ細かく反復編集することができます。また、構成要素について、その出現頻度による閾値指定選出や質的変数やクラスター変数のカテゴリ指定による、編集・抽出ができます。
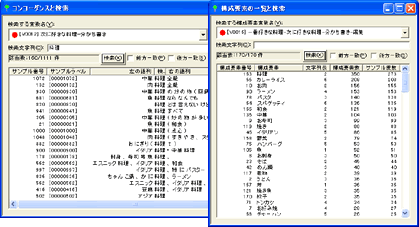
(4) いろいろな検索機能
任意の語句や単語が文章中のどのような文脈で使われているかコンコーダンス(用語検索と原文表示機能)で確認できます。また、構成要素やサンプルの検索機能も充実しており、きめ細かい探索を行うことができます。読み込んだ元の変数(原始変数)、あるいは生成した任意の変数について、前方・後方・完全一致による検索ができます。
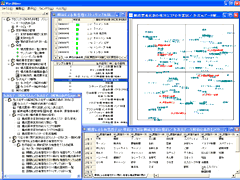
(5) データビューア
インポートしたデータや生成した変数の内容を相互に関連付けながら確認することができます。分析加工の全処理過程で得られた生成データ(情報)はすべてこのデータビューアで閲覧確認できます。また、それらの全情報をエクスポート機能により外部ファイルとして出力し、別の分析に備えることも可能です。
(6) 多次元データ解析
対応分析法、クラスター化法,有意性テスト、及びそれらに関連した種々の統計処理により、個々の回答や記述の意味内容、及びその規則性や典型を知り、同時に、類型・典型に含まれる個々の回答データの特徴を読み取ることや、少数例・特異例の特徴も知ることができます。

(7) データ・エクスポート
解析対象のデータ行列をはじめ、生成した変数情報や検索結果、処理過程や解析結果の数量化スコアなど、あらゆる処理場面でCSV形式によるファイルを出力することができます。これにより、他の統計解析ソフトウェアとの連携やビジュアル・ツールの活用が容易に行えます。
WordMinerの適用分野
テキスト型データが現れる場面は様々であり、そのあらゆる場面でWordMinerを活用することができます。WordMinerは、構成要素と定量的な属性や選択肢型設問などとの対比分析やポジショニングを行うことがひとつの特徴ですが、この他、新聞や雑誌記事、業務日報や活動報告書、メールや電子掲示板の投稿文書など、一般の文書型データの分析も得意としております。
例えば、次のような場面で、その有用性が確認されております。
・自由回答データと選択肢型設問データの併用による相互関連分析
・一般のアンケートにおける自由回答型設問の分類・類型化
・コール・センターや消費者センターに寄せられた「お客さまの生の声」の分析
・製造部門における工程管理や品質管理の定性情報の分析
・大学や研究機関における社会調査、行動分析
・行政機関における住民意識調査、「市民の声」の分析
・会議録や営業日報などの分類・整理
・新聞記事や雑誌、特許公報、論文などの動向・傾向分析